스크래핑, 크롤링
스크래핑
특정 사이트를 긁어서 가져오는 기술
크롤링
특정 사이트에서 여러 번 스크래핑을 하는 것이다. 사용시 주의 사항이 있는데 크롤링 해온 데이터를 상업적 목적으로 사용시 소송대상이 될 수 있으며 너무 많은 접속은 그 사이트의 회사 서버에 부하를 주게 돼 공격으로 판단으로 할 수 있다.
HTTP 응답 결과
어떤 페이지가 화면에 나올 때 Network에서 문서를 받아오는 순서는 처음으로 HTML을 받아오고 이후 그 문서에 있는 Link 태그 등을 통해서 바인딩 된 CSS, JS 파일을 가지고 온다 이렇게 주소창에서 주소를 입력하고 문서들을 받아오는 과정이 Http통신이라는 뜻이 된다.

주소창에 입력된 페이지에 대한 요청은 프론트엔드 서버에서 처리하게 된다. 그 후 프론트 서버에서는 요청에 대한 결과로 HTML을 반환하하고 이것이 우리가 보는 화면이다.
즉 브라우저의 주소창도 http 요청의 도구였다.
메타 태그와 Open Graphql

위의 이미지 처럼 우리가 링크를 카카오톡 디스코드 등으로 보내게 되면 아래에 사진과 사이트 이름, 설명 등이 뜨는 것을 볼 수 있다. 위를 구현해 주기 위해서는 hmtl의 헤드 부분에 meta 속성을 적용해 줘야 하며 그 예시 코드는 아래와 같다.

위 처럼 사이트에 meta 속성을 넣어주고 아래의 코드가 적용되 있는 곳 예를 들어 카카오톡이나 디스코드 슬랙등에서 포털 사이트의 주소를 넣어주게 되면 위의 이미지 처럼 출력되게 된다.

하지만 다이나믹한 상황에서도 사용이 가능하도록 코딩을 하기 위해서는 서버 사이드 랜더링이 필요하게 된다. 그 이유는 초기 랜더링 시 백엔드 요청을 하지 않기 때문에 메타 태그가 비게 되는 문제가 생길 수 있습니다.
문제 코드

문제 예시 그림
위와 같은 이유로 서버사이드 렌더링이 필요하게 됩니다.
서버 사이드 렌더링 OG 태그 만들기 예시 코드

useQuery를 사용하는 대신 getServerSideProps를 사용하게 된다.
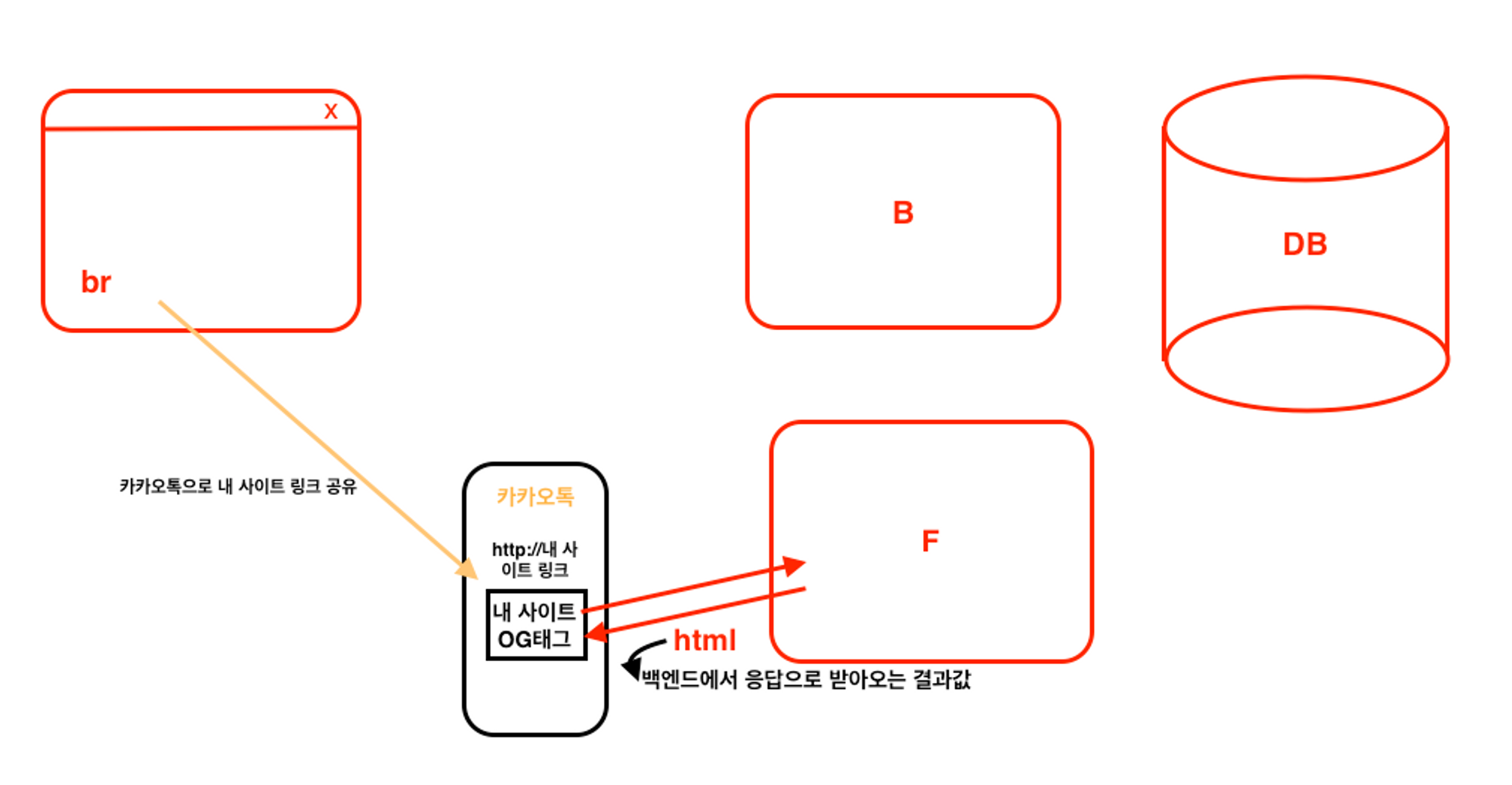
위의 과정을 그림으로 그린 이미지

SEO(검색 엔진 최적화)
SEO는 말 그대로 검색 엔진(네이버, 구글 등)에 노출되기 가장 좋게 만드는 방법으로 서버사이드 렌더링이 필요한 이유 중 하나다.
검색 엔진의 검색봇이 24시간 여러 사이트를 돌며 해당 사이트가 어떤 사이트인지 확인하게 되는데 서버 사이드 렌더링이 안된 곳의 경우 이 과정에서 비어 있게 되어 검색봇이 페이지를 판단할 수 없기 때문이다.
알고리즘

코드 실행 결과
'TIL' 카테고리의 다른 글
| 프론트 엔드 8주 2일차 (0) | 2023.05.04 |
|---|---|
| 프론트엔드 8주 1일차 (0) | 2023.05.04 |
| 프론트 엔드 7주 3일차 (0) | 2023.05.01 |
| 프론트 엔드 7주 2일차 (2) | 2023.04.25 |
| 프론트 엔드 7주 1일차 (0) | 2023.04.24 |



