검색 프로세스 이해 (ES, Redis)
브라우저에서 검색을 요청하면 백엔드에서 데이터베이스 내부의 데이터들에서 요청받은 검색어를 통해서 모든 데이터를 찾게 되는데 이걸 full-scan이라고 합니다. 하지만 이런 경우 데이터를 모두 대조해보는데 시간이 오래걸리기 때문에 이를 해결하기 위해서 검색을 위해 단어 단위로 나누어 이를 색인으로 저장해서 그 단어의 위치를 저장하는 방식으로 더욱 빠르게 검색하는 방법을 reverse index 방식이라고 부른다. reverse index을 만들어주는 도구로 elastic search가 있으며 이 방식은 디스크(비휘발성 메모리)에 저장되기 때문에 데이터의 유지와 안정성이 높아진다는 특징이 있지만 속도가 떨어지게 된다는 단점이 있다.
위의 문제를 해결하기 위해서 메모리 저장 방식인 Redish를 함 께 적용하는 방식을 이용한다. 디스크에서 검색으로 불러낸 데이터를 일정 시간 동안 메모리에 저장해두고 다시 검색으로 인해서 호출되면 메모리에서 이를 불러오는 것으로 속도 문제를 어느 정도 해결 가능합니다.
검색 버튼 없이 onChange만을 이용해서 검색 기능을 만들게 되면 생기는 문제가 있는데 바로 검색창에 변화가 생길 때 마다 refetch를 진행하기 때문에 쓸데없는 데이터 교환이 이뤄지고 이것이 계속 반복되게 되면 쓸데없는 자원을 사용하게 된다. 이걸 개선하고 위해서 Debouncing을 사용해야 한다.
Debouncing
디바운싱이란 여러 번 발생하는 이벤트를 한 개의 그룹으로 묶어 한꺼번에 보내는 방식으로 마지막으로 이벤트가 발생한 시점으로부터 일정 시간 동안 이벤트가 발생하지 않으면 실행되는 방식으로 주로 검색 기능에서 쓰이게 됩니다.

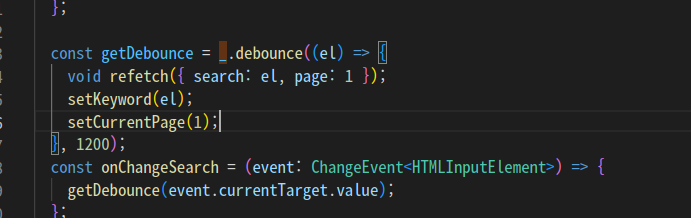
위의 예시 코드 처럼 lodash 라이브러리를 import해서 아래 예시 코드처럼 사용할 수 있습니다.
Throttling
쓰로틀링은 디바운싱과 다르게 처음 이벤트가 발생하면 이후 발생하는 이벤트는 일정 시간동안 무시하는 방식으로 주로 스크롤 기능에서 쓰이게 됩니다.
알고리즘

최대 공약수와 최대 공배수 문제로 최대 공약수를 구하는 유클리드 호제법을 사용한 방법이다. 그리고 최소공배수는 두 수의 곱에 최대공약수를 나누어서 구할 수 있었다.
오늘 코딩 결과
'TIL' 카테고리의 다른 글
| 프론트엔드 5주 3일차 로그인과 암복호화 (0) | 2023.04.13 |
|---|---|
| 프론트 엔드 5주 2일차 매개변수와 recoil (0) | 2023.04.11 |
| 프론트 엔드 4주 4일차 이미지 프로세스 (0) | 2023.04.07 |
| 프론트 엔드 4주 3일차 백엔드, firebase (0) | 2023.04.06 |
| 프론트엔드 4주 2일차 Back-End (0) | 2023.04.04 |



